
Problem Definition
The scientific literature presents several ways to approach the problem, but we were more specifically interested in the answer selection task. This task aims to predict the correct answer among a set of candidate answers.

It assumes that there is always a correct answer for each question. However, in a real Q&A system, sometimes we do not want to provide an answer, for example if a user asks an out-of-domain question. The answer triggering task offers this possibility.

System Definition
To accomplish the answer triggering task for a given question, the chosen implementation performs two subtasks:
- A machine learning model (a classifier) accepts as input a vector representation of the question and returns the probabilities by class. Each class is associated with a question-answer pair.
- The highest probability is compared to a threshold to determine whether the answer will be returned or not.
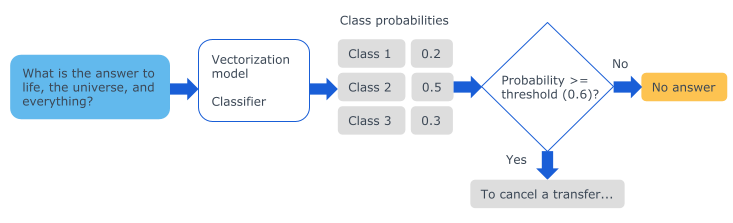
Experiments were then carried out to find the best combination of vectorization model and classifier to perform the first subtask.
Experiments
For the experiments, the banking dataset BANKING77, created by the conversational solutions company PolyAI, was used. The vectorization model and classifier combinations were evaluated on the test set with the accuracy metric, which calculates the percentage of correct predictions.
Vectorization Models
Among the different vectorization models, the one that performed the best is Google’s Universal Sentence Encoder (USE). It is a neural network pretrained simultaneously on several semantic tasks which accepts a text as input and outputs a sentence embedding (a vector representation of the sentence). The pretraining is done on large text corpora like Wikipedia, which allows it to capture the semantic similarity of sentences never seen before, as shown in the example below.
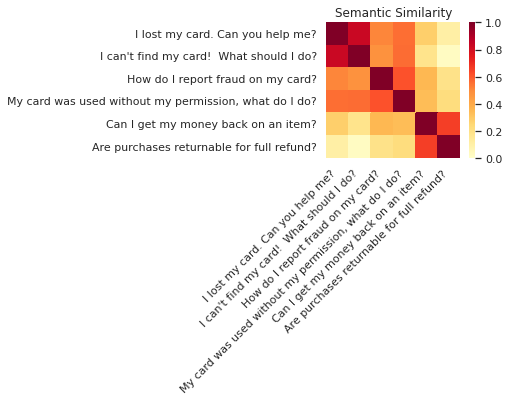
Semantic similarity of sentences taken from BANKING77 with USE. Reference
Classifiers
The evaluated classifiers include a k-nearest neighbor classifier (KNN) and a neural network. The main advantage of the KNN over the neural network is that it does not need to be trained, it just memorizes the training data. Adding new questions to the model therefore does not require retraining. Another advantage is that its predictions are interpretable. To predict the class of a test example, the KNN finds its k-nearest neighbors and returns the majority class. The number of neighbors as well as the distance function are configurable hyperparameters.
To illustrate how a KNN works, a simplified example is provided below for a binary classification problem with 2-dimensional data.
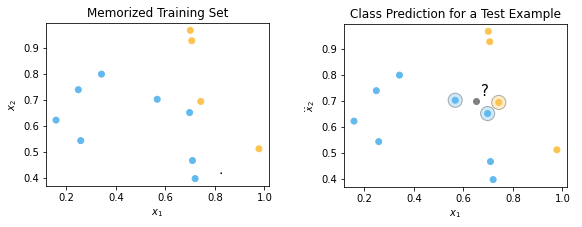
Example for a KNN with k=3 and Euclidean distance. For the test example in gray, we will
predict the class in blue (majority class among the 3 nearest neighbors).
First, experiments were performed with a KNN with cosine distance. Afterwards, other experiments were carried out with a learned distance function (metric learning) in order to improve performance. The purpose of the algorithm was to bring together the examples of the same class and to distance the examples belonging to different classes. In both cases, the accuracy obtained with the neural network was superior, which led to the latter being chosen as the classifier.
System Evaluation
The experiments described above have established that the best model was the one combining the Universal Sentence Encoder with an MLP. To evaluate this model, a comparison was performed on the answer triggering task with the NLU intention classification models of Dialogflow ES and Rasa. To do this, a new “out_of_scope” intent containing questions about COVID-19 has been added to the BANKING77 test set. For all models, rejecting out-of-domain examples proved more difficult than properly classifying in-domain examples. However, overall, it was the USE model combined with a neural network that stood out. This evaluation has therefore demonstrated that this model can be used to develop an effective and efficient Q&A system.
For more details on the models used, the methodology followed and the results of the experiments, we invite you to consult this article.
