
Dans notre série précédente d’articles sur le développement d’applications conversationnelles à l’aide de Rasa (actuellement disponibles en anglais seulement), nous avons décrit notre approche pour l’ajout du support VoiceXML à la plateforme Rasa et le développement d’une démo bancaire convaincante utilisant des patrons de dialogues évolués. La stratégie de gestion de dialogue sur mesure créée pour ce projet, basée sur une pile d’actions, était entièrement programmatique. Bien que cette stratégie nous a permis de répondre à nos exigences complexes, nous n’en étions pas tout à fait satisfaits (nous élaborerons là-dessus dans un prochain article) et avions l’impression de passer à côté de ce qu’offre Rasa en ne tirant pas profit de son potentiel d’apprentissage machine.
Nous avons résolu ceci d’abord en développant un bot de soutien technique à interface texte à partir d’un corpus de conversations réelles et avons créé un prototype utilisant les “stories” basées sur l’apprentissage machine de Rasa. À la lumière de l’expérience et de la connaissance ainsi gagnées, nous avons revu de fond en comble notre stratégie de gestion du dialogue pour la rendre plus compatible avec les autres composantes de Rasa (plus à ce sujet dans la prochaine partie de cette série). Nous avons également créé un environnement de développement d’applications RVI réutilisable qui nous permettra d’offrir à nos clients des expériences conversationnelles remarquables.
Nous avons maintenant complété une première version du nouvel environnement de développement et avons entièrement réimplanté notre démo bancaire. Les composantes principales de cet environnement de développement sont:
- Gestion du dialogue (avec environnements de tests unitaires et d’intégration adaptés)
- Génération de réponses (le thème principal de cet article)
- Connecteur VoiceXML (pour communiquer avec la plateforme VoiceXML)
Cette nouvelle série d’articles de blogue s’attardera à la gestion du dialogue et à notre nouvelle approche de génération de réponses.
Sans plus tarder, passons maintenant au sujet principal de cet article: la génération de réponses.
Pourquoi un serveur NLG?
Avec Rasa, les réponses du bot sont regroupées par défaut dans le fichier de domaine. Bien que cette approche soit adéquate pour les applications textuelles basiques, nous en avons rapidement atteint les limites avec nos exigences applicatives pour la RVI. Le premier enjeu que nous avons rencontré est le multilinguisme; nous voulons construire une application unique supportant plusieurs langues (le français et l’anglais la plupart du temps) et Rasa n’offre aucun support dans le fichier de domaine pour ce faire. Nous devons aussi produire des réponses complexes, structurées et dynamiques pour lesquelles le mécanisme élémentaire d’interpolation de variables n’est pas suffisant. Nous avons dû créer des structures JSON contenant des listes variables d’éléments (grammaires, concaténation de segments audio) et d’objets avec des propriétés dynamiques (seuils, délais, etc.) pour arriver à exprimer la richesse du VoiceXML.
Entre en jeu le serveur NLG (Natural Language Generation ou “génération de langage naturel”), qui est un mécanisme d’extension offert par Rasa et qui permet d’externaliser la génération de réponses dans un service séparé. En implémentant une interface REST simple, nous pouvons générer toutes les réponses que nous voulons à partir d’un gabarit spécifique et de l’état de la conversation (tracker). Ceci nous permet de construire des réponses qui suivent notre protocole JSON VoiceXML, qui lui sera utilisé par la passerelle Rivr. Pour vous rafraîchir la mémoire sur ce sujet, vous pouvez consulter l’excellent billet (disponible en anglais seulement) de ma collègue Karine Déry!
L’intérêt de cette approche est que nous pouvons l’utiliser avec les stories Rasa, mais aussi avec les actions, où nous avons plus de contrôle par le biais de variables complexes, d’indexes de messages d’erreurs progressifs, et bien plus encore. Dans tous les cas, nous conservons la valeur de la langue dans le tracker en utilisant une catégorie sous-spécifiée particulière (“unfeaturized slot” dans la terminologie de Rasa).
Ressources, ressources, ressources…
Le développement d’une application RVI en VoiceXML requiert qu’on fournisse les ressources nécessaires à la plateforme VoiceXML.
Segments audio
Bien que la synthèse de la parole (TTS ou “text-to-speech”) se soit énormément améliorée ces dernières années, les enregistrements effectués par des narrateurs professionnels donnent encore des résultats plus expressifs et naturels. Un des principaux défis d’utiliser des enregistrements est d’obtenir un résultat fluide lorsqu’on génère des entités dynamiques complexes comme les dates et les montants. Pour ce faire, nous utilisons habituellement la concaténation de fichiers audio, qui exige une segmentation adéquate des éléments à concaténer (des fichiers audio séparés pour les jours, mois et années pour une date, par exemple) ainsi que l’intonation appropriée. On doit alors écrire du code qui convertira correctement une valeur d’entité vers la bonne séquence audio, qui elle sera retournée par le serveur NLG.
Par exemple, pour notre démo bancaire, jouer le montant 507,18$ requiert l’utilisation de la séquence suivante:
- amount/500_mid.wav (cinq cent…)
- amount/07_dollars_rising.wav (sept dollars…)
- amount/and_18_cents_final (et dix-huit cents.)
Dans cet exemple, nous utilisons une intonation finale pour le dernier segment puisqu’il se trouve en fin de phrase. S’il s’était trouvé en milieu de phrase, un patron intonatif différent aurait été choisi. L’enregistrement de grandes quantités de petits segments audio pour la concaténation exige un narrateur constant, un bon coach vocal et un post-traitement rigoureux des fichiers pour maximiser la fluidité.
Grammaires de reconnaissance
Nous utilisons actuellement des grammaires SRGS et l’engin de reconnaissance de la parole de Nuance pour interpréter les requêtes de l’utilisateur, mais nous pourrions également utiliser des grammaires statistiques (SLM/SSM). Les deux nous permettent d’obtenir un résultat NLU (interprétation sémantique) sans recourir à l’engin NLU de Rasa (ou autre). Ces grammaires permettent de contraindre ce que l’usager peut dire selon le contexte et peuvent être optimisées pour maximiser la performance en fonction de ce qui est demandé à l’usager, tout en supportant les digressions.
D’autres approches sont possibles, en l’occurrence la combinaison d’un engin de transcription automatique (“speech-to-text” ou STT) et d’un engin d’interprétation sémantique distinct (par exemple, Rasa NLU). Nous explorerons ces possibilités plus à fond mais pour le moment, l’utilisation de grammaires offre un bon équilibre entre la performance et la simplicité.
Distribution des ressources
Dans notre implémentation actuelle, le serveur NLG est aussi responsable de fournir ces ressources statiques à la plateforme VoiceXML (fichiers audio) et à la reconnaissance vocale de Nuance (grammaires). Dans l’éventualité où nous aurons besoin de grammaires dynamiques (pour reconnaître certains éléments provenant du profil de l’utilisateur, notamment), il sera facile de rehausser notre serveur pour les générer.
Construire une réponse complète
Les divers éléments de réponse de nos applications sont définis dans un fichier structuré de format YAML qui relie l’état du dialogue, les ressources associées ainsi que le contenu dynamique.
Voici un premier extrait de notre fichier de ressources en français qui décrit notre menu principal (un fichier équivalent avec la même structure existe pour l’anglais):

Nous pouvons voir que les réponses, qui sont composées de messages et de grammaires, sont organisées de manière hiérarchisée qui reflète la structure de l’application. Faire référence à une réponse dans une story Rasa est aussi simple que d’utiliser une action utter (par exemple, utter_main_menu.initial). Le faire dans une action est aussi très simple.
En y regardant de plus près, nous pouvons faire quelques observations intéressantes:
- La grammaire des intentions (intents grammar, spécifiée à l’aide la clé spéciale _grammars) est définie une fois au premier niveau du menu principal et s’applique à chaque réponse (à moins qu’on lui en substitue une autre) pour éviter la répétition.
- Pour chaque réponse de type reentry (repasser par le menu), nous remplaçons les grammaires actives pour ajouter le support pour allDone, qui reconnaît que l’usager n’a pas d’autre requête (en disant “non merci” ou “c’est tout”, par exemple).
- Il y a des messages d’erreur progressifs lorsque l’usager ne dit rien (no_input) ou lorsqu’il y a une erreur de reconnaissance (no_match).
Voici un autre exemple intéressant:
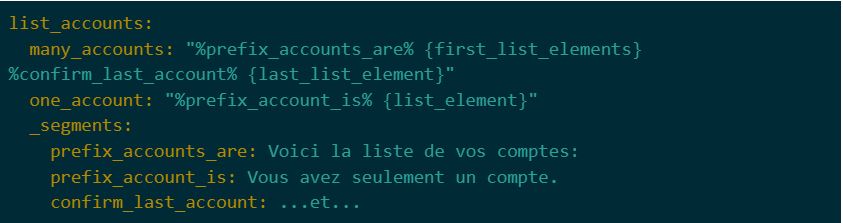
Nous vous présentons ici notre mini gabarit de message qui est utilisé pour la concaténation lorsque nous devons jouer du contenu dynamique. Nous pouvons voir comment sont définis les éléments statiques du message sous la clé spéciale _segments de telle sorte qu’on puisse facilement s’y référer dans le gabarit (en utilisant %segment_name%). Les éléments dynamiques doivent faire partie de la requête au serveur NLG et peuvent inclure d’autres références à des segments ou encore des instructions pour la génération de synthèse vocale (TTS).En somme, en recevant une requête adéquate, le serveur NLG va trouver le gabarit de réponse correspondant, identifier les ressources nécessaires, injecter les variables et assembler une réponse complète qui sera utilisable par le connecteur VoiceXML.
Concernant l’intégrité des ressources
Une application peut rapidement devenir complexe et comporter de grandes quantités de ressources. Pour s’assurer que chaque grammaire est correctement définie et que chaque segment audio est enregistré (et qu’il n’y a pas de fichiers superflus qui traînent), nous avons développé des rapports d’intégrité qui vérifient que chaque ressource incluse dans notre fichier de définition fait référence à un fichier existant. Ces rapports peuvent en outre être utilisés par l’équipe responsable de l’enregistrement des messages.
La seule pièce manquante à notre édifice est une liste de références applicatives permettant de nous assurer que les ressources de notre fichier de définition sont réellement utilisées par l’application.
Comme vous aurez pu le constater, le serveur NLG est une composante fondamentale de notre approche de développement de RVI conversationnelles utilisant Rasa. Il nous permet de facilement spécifier des réponses multilingues et contextuelles composées de messages et de grammaires auxquels on peut faire référence aisément dans les stories ou les actions sur mesure. Ne manquez pas la suite de notre série, où nous allons présenter notre nouvelle approche pour la gestion du dialogue!
