
Dans notre métier, on entend souvent “Après avoir fait l’assistant vocal, on pourra utiliser le dialogue pour ajouter un chatbot sur notre site!!” ou encore “Maintenant qu’on a notre chatbot, faire un voicebot sera si facile”. À première vue, il suffit d’ajouter ou d’enlever une couche de reconnaissance de la parole (speech-to-text, STT) et de synthèse de la parole (text-to-speech, TTS) à l’un pour obtenir l’autre. Pourtant, l’expérience nous a appris qu’il faudrait un coup de baguette magique pour que ce soit aussi simple, et à travers ce post, j’essaierai de le démontrer à l’aide de quelques exemples.
Génération de l’extrant
Présentation d’informations complexes
Pour un chatbot, il est possible de complémenter le texte par des images, des hyperliens, des carrousels, etc. Certains cas d’utilisation, comme l’aide à la navigation, ou des suggestions d’achats, sont impensables sans ces outils.
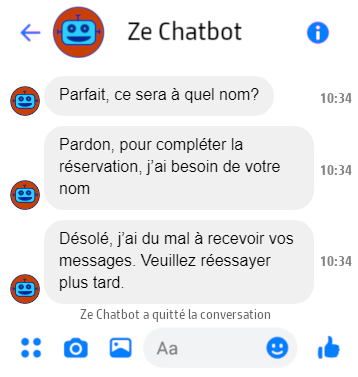
Dans d’autres cas, plusieurs interactions vocales pourraient être nécessaires pour obtenir le même résultat qu’un seul extrant visuel complexe. Voici, par exemple, ma meilleure tentative de reproduction extrant pour extrant d’un bot de prise de rendez-vous:
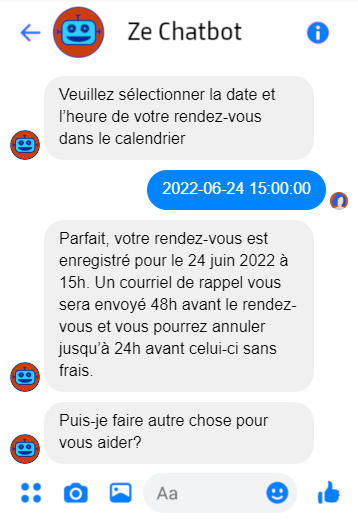
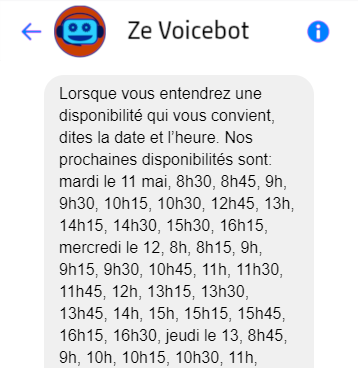
Traces des interactions précédentes
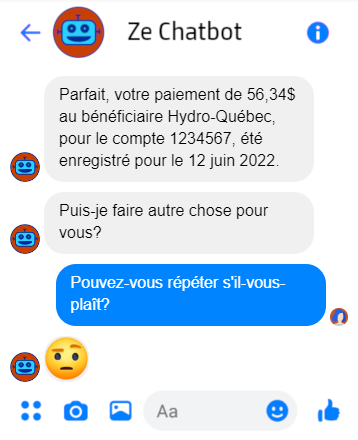
Que fait un chatbot si l’utilisateur est inattentif, a mauvaise mémoire, ou a oublié de mettre ses lunettes? Rien! L’extrant reste là pour que l’utilisateur le relise comme bon lui semble, ce qui rend certains cas nécessaires à l’oral très inutiles à supporter à l’écrit:
Persona et rendu
La persona (caractéristiques démographiques, niveau de langue, personnalité) de l’agent virtuel, ainsi que sa cohérence, est importante dans les deux modes. Alors qu’en mode textuel il faut penser à la facture visuelle du chatbot, en mode vocal, il faut chercher une voix qui représente les caractéristiques désirées tout en étant naturelle, et cela peut restreindre nos options. Essayer de créer un agent vocal informel, par exemple, peut être quasi-impossible, surtout en utilisant le TTS au lieu d’une voix enregistrée (qui a aussi ses limitations).
Support de multiples canaux
Finalement, même si nos cas d’utilisation sont indépendants du canal, notre persona très simple et notre agent très verbal, il est clair qu’il faut minimalement pouvoir jouer des messages différents selon le canal, ne serait-ce que pour inclure du SSML dans les messages audio. Malheureusement, certains engins de dialogue supportent difficilement plusieurs canaux et cela peut faire exploser la complexité d’implémenter un agent commun.
Interprétation de l’intrant
“Qu’en est-il de l’autre sens? L’utilisateur n’enverra pas d’images ou de carrousels au chatbot, sûrement traiter l’intrant ne peut pas être si différent”. Je répondrai à ceci par une dramatisation. Suivons Bob, qui essaie d’exprimer son besoin à un agent vocal:
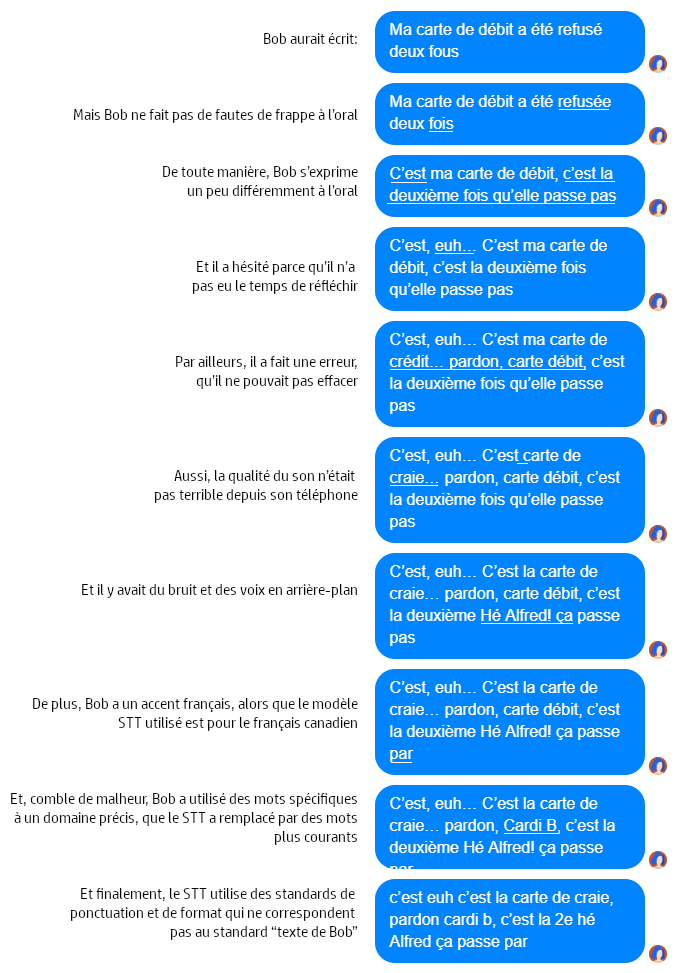
Bien entendu, Bob et sa malchance légendaire n’existent pas, mais les cas présentés sont tirés de la réalité. Même si certains modèles de STT peuvent maintenant ignorer les “euh”, les bruits et les voix secondaires, la transcription comportera toujours son lot d’erreurs.
Incertitude
Il existe des moyens de diminuer ces erreurs ou leurs impacts, que ce soit via la configuration de l’engin, des transformations systématiques sur la transcription, ou l’adaptation du modèle TALN aux phrases reçues. Il reste malgré tout une incertitude supplémentaire liée au STT dont il faut tenir compte dans le développement d’une application vocale.
Stratégies de gestion de l’incertitude
Pour augmenter notre confiance en l’interprétation de l’intrant, on utilisera dans le dialogue d’un agent vocal plus de stratégies de gestion de l’incertitude que dans un agent textuel. On pense par exemple à:
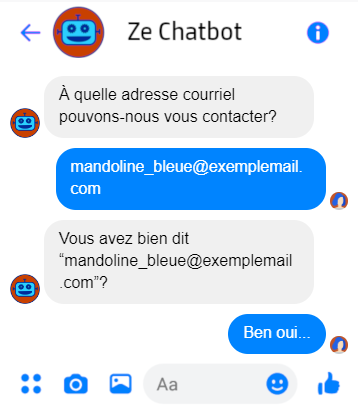
- Ajouter une étape de confirmation explicite ou implicite d’une intention ou entité
- Ajouter une étape de désambiguïsation de l’intrant pour des intentions trop similaires
- Supporter les changements/corrections
Choix des cas d’utilisation
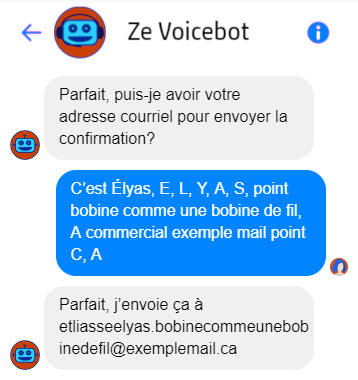
Les adresses, les courriels ou les noms de personnes sont des informations difficiles à transcrire correctement pour de multiples raisons, mais peu problématiques à l’écrit. Si certaines sont critiques pour un cas d’utilisation, il pourrait être très complexe, risqué, ou inadéquat pour l’expérience utilisateur de l’implémenter vocalement.
Gestion du temps réel
La dernière grande différence entre les conversations vocales et textuelles est la gestion du temps. Une conversation textuelle est asynchrone: l’intrant est reçu en un bloc, et la réponse qui suit est envoyée en un bloc. L’audio, lui, est transmis en continu, le temps doit donc être géré en conséquence.
Réponse rapide et expérience utilisateur
En discussion vocale, il est inhabituel de ne pas avoir de réponse en quelques dixièmes de seconde, alors qu’en mode texte, c’est tout à fait normal. Un trop long silence au bout du fil est malaisant, et même s’il est possible de jouer des sons ou de la musique pour les attentes, entre deux interactions régulières, les “…” sont irremplaçables. Il est donc beaucoup plus critique en mode voix de s’assurer que le système est rapide et d’avertir l’utilisateur en cas d’opération plus longue.
Interruptions
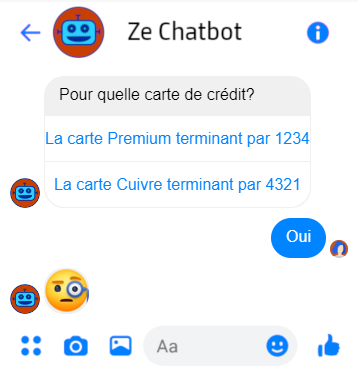
Parce que l’extrant vocal a une durée, l’utilisateur peut essayer d’interrompre un agent vocal. Supporter les interruptions correctement implique une complexité technique additionnelle, mais aussi quelques impacts sur le dialogue. On voudra par exemple faire l’hypothèse que si l’utilisateur dit “oui” lorsqu’on présente plusieurs options, cela signifie qu’il choisit la première, et supporter ce cas.
Le silence de l’utilisateur
Quoiqu’un agent virtuel soit immunisé au malaise des silences, le traitement de ce qu’on appelle communément un no-input diffère grandement selon le mode. En voix, quelques secondes de silence signifient généralement que l’utilisateur hésite ou que le son de sa voix est trop bas; on jouera donc un message d’aide approprié.
En mode texte, il est inutile de harceler l’utilisateur de messages d’erreur car l’absence d’intrant est traité comme toute inaction sur un site web: après un temps déterminé, l’utilisateur sera déconnecté si nécessaire, et la conversation terminée.
Alors, finalement…
Que répond-on alors à la question: “Que peut-on réutiliser d’un agent vocal pour créer un chatbot ou vice-versa?” La réponse est très nuancée et un peu décevante. Passer d’un agent vocal à un chatbot permettra généralement plus de réutilisation car le premier est généralement plus contraignant: peut-être qu’il suffira d’adapter un peu les messages, d’ajouter ou d’enlever quelques chemins de dialogues.
Cependant, dans les deux cas, il sera important de prendre un pas de recul et de ré-évaluer nos cas d’utilisation et notre persona: sont-ils appropriés, faisables et réalistes sur ce nouveau canal? Pour ce qui survit à ce questionnement, les règles d’affaires et les flux haut-niveau du dialogue pourront probablement être réutilisés. Le modèle TALN (données textuelles, organisation des intentions et entités) et les messages de l’un pourront servir de base à l’autre, mais seront appelés à changer. En effet, l’approche devra être adaptée aux résultats de tests utilisateurs et collectes de données, afin que l’expérience utilisateur ne souffre pas au profit de la simplicité du développement.
