
Définition du problème
La littérature scientifique présente plusieurs façons d’aborder le problème, mais nous nous sommes intéressés plus spécifiquement à la tâche de sélection de réponse. Cette tâche vise à prédire la réponse correcte parmi un ensemble de réponses candidates.
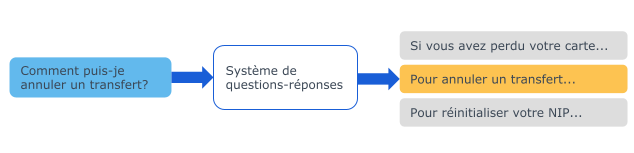
Elle suppose qu’il existe toujours une réponse correcte pour chaque question. Cependant, dans un système réel de questions-réponses, on souhaite parfois ne pas fournir de réponse, par exemple si un utilisateur pose une question hors domaine. La tâche de sélection optionnelle de réponse (answer triggering) offre cette possibilité.
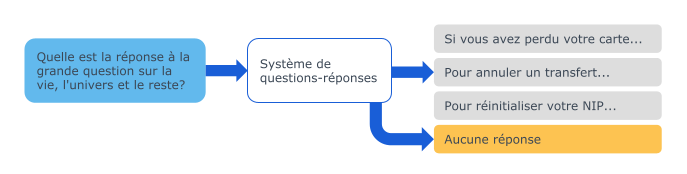
Définition du système
Pour accomplir la tâche de sélection optionnelle de réponse pour une question donnée, l’implémentation choisie exécute deux sous-tâches:
- Un modèle d’apprentissage automatique (un classifieur) accepte en entrée une représentation vectorielle de la question et retourne les probabilités par classe. Chaque classe est associée à une paire question-réponse.
- La probabilité la plus élevée est comparée à un seuil pour déterminer si la réponse sera retournée ou non.
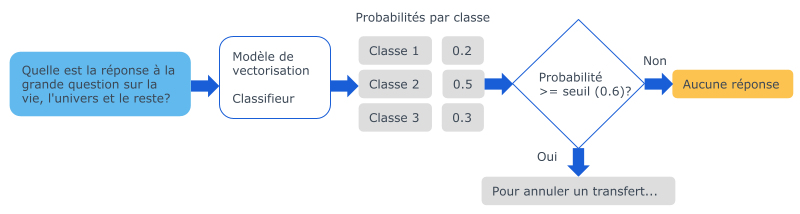
Des expériences ont ensuite été réalisées pour trouver la meilleure combinaison de modèle de vectorisation et de classifieur pour réaliser la première sous-tâche.
Expériences
Pour les expériences, l’ensemble de données bancaires BANKING77, créé par l’entreprise de solutions conversationnelles PolyAI, a été utilisé. Les combinaisons de modèle de vectorisation et de classifieur ont été évaluées sur l’ensemble de test avec la métrique d’exactitude (accuracy), qui calcule le pourcentage de prédictions correctes.
Modèles de vectorisation
Parmi les différents modèles de vectorisation, celui qui a le mieux performé est le Universal Sentence Encoder (USE) de Google. C’est un réseau de neurones préentraîné simultanément sur plusieurs tâches de nature sémantique qui accepte en entrée un texte et produit en sortie un plongement de phrase (une représentation vectorielle de la phrase). Le préentraînement est fait sur de très grands corpus de texte comme Wikipédia, ce qui lui permet de bien capturer la similarité sémantique de phrases jamais vues au préalable, comme on peut voir dans l’exemple ci-dessous.
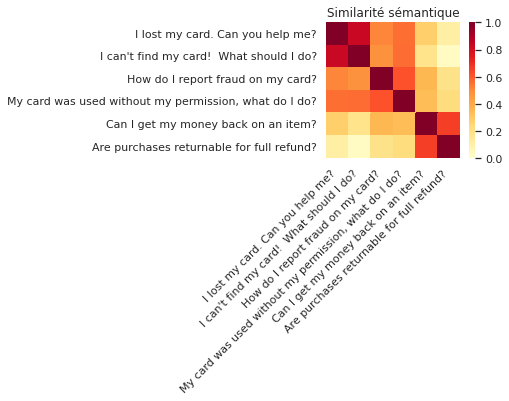
Similarité sémantique de phrases tirées de BANKING77 avec USE. Référence
Classifieurs
Parmi les classifieurs évalués, on compte notamment un classifieur des k plus proches voisins (KNN) et un réseau de neurones. L’avantage principal du KNN par rapport au réseau de neurones est qu’il n’a pas besoin d’être entraîné, il ne fait que mémoriser les données d’entraînement. Ajouter de nouvelles questions au modèle ne nécessite donc pas un réentraînement. Un autre avantage est que ses prédictions sont interprétables. Pour prédire la classe d’un exemple de test, le KNN trouve ses k plus proches voisins et retourne la classe majoritaire. Le nombre de voisins ainsi que la fonction de distance sont des hyperparamètres configurables.
Pour illustrer le fonctionnement du KNN, un exemple simplifié est fourni ci-dessous pour un problème de classification binaire avec des données en 2 dimensions.
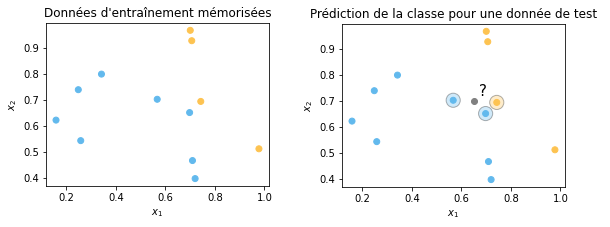
Exemple pour un KNN avec k=3 et distance euclidienne. Pour l’exemple de test en gris, on
prédira la classe en bleu (classe majoritaire parmi les 3 plus proches voisins).
Dans un premier temps, des expériences ont été réalisées avec un KNN avec distance cosinus. Dans un deuxième temps, d’autres expériences ont été réalisées avec une fonction de distance apprise (metric learning) dans le but d’améliorer la performance. L’algorithme utilisé avait pour but de rapprocher les exemples d’une même classe et éloigner les exemples appartenant à des classes différentes. Dans les deux cas, l’exactitude obtenue avec le réseau de neurones était supérieure, ce qui fait en sorte que ce dernier a été choisi comme classifieur.
Évaluation du système
Les expériences décrites précédemment ont permis d’établir que le meilleur modèle était celui combinant le Universal Sentence Encoder avec un MLP. Pour évaluer ce modèle, une comparaison a été effectuée sur la tâche de sélection optionnelle de réponse avec les modèles de classification d’intentions des engins NLU de Dialogflow ES et Rasa. Pour ce faire, une nouvelle intention “out_of_scope” (hors domaine) contenant des questions sur la COVID-19 a été ajoutée à l’ensemble de test de BANKING77. Pour tous les modèles, rejeter des exemples hors domaine s’est avéré plus difficile que bien classifier les exemples appartenant au domaine. Cependant, dans l’ensemble, c’est le modèle USE combiné à un réseau de neurones qui s’est démarqué. Cette évaluation a donc démontré que ce modèle peut être utilisé pour développer un système de questions-réponses performant et efficace.
Pour plus de détails sur les modèles utilisés, la méthodologie suivie et les résultats des expériences, nous vous invitons à consulter cet article.
