
Chatbots come in multiple forms and can serve many different purposes. Without pretending to exhaustivity, we can mention
- the task-oriented bots, that aim to assist a user in a given set of transactional tasks, like, for example, banking operations
- the chit-chat bots, whose primary objective is to mimic casual conversation
- and the question answering bots, whose purpose is to, you guessed it, answer user’s questions.
These categories are not mutually exclusive: A task-oriented bot can support some level of small talk, and question answering bots can assist the user in some tasks. These are to be perceived as paradigms more than strict definitions.
In this article, we will focus on the concept of the question answering chatbot, and more specifically on the implementation of this concept in Dialogflow, using Knowledge connectors (still a beta feature at the moment of writing).
About Dialogflow FAQ knowledge connectors
Knowledge connectors are meant to complement the intents of an agent and offer a quick and easy way to integrate existing knowledge bases to a chatbot. Dialogflow offers two types of knowledge connectors: FAQ and Knowledge Base Articles. Here we will mostly focus on the FAQ knowledge connector, which models the knowledge bases as a list of question-answer pairs (QA pairs).
Each QA pair in a FAQ knowledge connector can be seen as a special kind of intent that has a single training phrase and a single text response. At first sight, the main advantages of a FAQ knowledge connector over defined intents seem to be the ease of integrating external knowledge bases and the fact that, contrary to defined intents, more than a single response can be returned (which can be convenient for a search mode).
Are there any other advantages? One of our hypotheses when we started this work was that knowledge connectors would be able to leverage the answer in the QA pair when matching the query, not just the question. This is not explicitly mentioned in the documentation, but it would make sense for two reasons. First, it’s hard to believe that any NLU engine can effectively learn from a single training phrase. There are always many ways to ask a question that don’t look at all like the training phrase. Second, FAQ data sources often have long answers that could conceivably be correct answers to a wide range of questions other than the one provided. When trying to find the correct answer to a user query, it would therefore make sense for the engine to focus as much on finding the answer that best answers the query as on finding the question that best matches the query.
Anatomy of the Knowledge Base
The knowledge base we used was taken from the Frequently Asked Questions (FAQ) section of the website of a North American airport. It contains more than a hundred QA pairs, separated in a dozen categories. Each category contains a number of subcategories ranging from only one to about ten.
While some questions have straightforward answers, others have complex, multi-paragraphs ones. All the answers are primarily composed of text, but many also contain tables, images, and some even contain videos. Many answers also have hyperlinks leading to other parts of the FAQ or external pages.
Minor surgery on the Knowledge Base
While analyzing the knowledge base, we found that several questions only made sense within the context of the category and sub-category in which they appear. For instance, in the Parking section, we have the question “How do I reserve online?”. The FAQ context makes it clear that this is a question about parking reservation, but this information is lost when modeling the knowledge base as a CSV-formatted list of question-answer pairs (QA pairs). We therefore had to modify several of the original questions so that they could be understood without the help of any context. So, in the example above, the question was changed to: “How do I reserve a parking space online?”.
What questions users ask
The airport website offers users two distinct ways to type queries to get answers: one that clearly looks like a search bar and another one that looks like a chat widget that pops when clicking a “Support” button on the bottom right of the web page. Both of them do the exact same thing: They perform a search in the knowledge base and return links to the most relevant articles. However, we believe that the chat-like interface entices more complex, natural queries since the users may believe they are entering a chat conversation.
The airport provided us with a set of real user queries collected from the two query interfaces. This is very important because this tells us what questions users are really asking and it provided us with real user data for our experiments.
Of course, we had to do some cleaning on that data set, as a good number of queries were not relevant for our purpose. Things like digit strings (most likely phone numbers and extensions), flight numbers with no other indications, or purely phatic sentences (for example, “how are you?”). We also observed that the queries could be separated into two groups: either they were really short and to the point, with one or two words at most, or they were long and complex, with lots of information, details, and usually formulated as a question.
Augmenting the corpus
Once the data set was cleaned, we ended up with about 300 queries (down from a little more than 1500!). Clearly, this would not be sufficient for our experiments, so we decided to collect additional data that, we hoped, would still be representative of real user queries.
We considered using crowdsourcing solutions (like Amazon Mechanical Turk) but ultimately decided to try other options. Instead, we used the People also ask and Related searches functionalities of Google Search to glean additional user data. We would start with a user query (real or fabricated) and collect the related questions proposed by Google. One interesting feature of the People also ask functionality is that every time we expand one of the choices, it proposes several additional related questions. This way, we ended up collecting about 300 additional queries with little to no effort, effectively doubling the number of queries we had.
At the same time, we also organized an internal data collection at Nu Echo, where our colleagues would have to write plausible user queries based on general categories that we assigned to them. This gave us over 400 hundred additional queries, bringing our total to about a thousand.
Annotating the corpus
Annotating the corpus consists in manually determining which QA pair in the knowledge base, if any, correctly answers each of the queries in the corpus. While this sounds simple, it proved to be a surprisingly difficult task. Indeed, the human annotator has to carefully analyze each potential answer before deciding whether or not it’s a correct response to the query. For some queries, there was no correct answer, but there were one or several QA pairs that provided relevant answers.
What we ended up doing was separate the corpus in 3 categories:
- Queries with a correct answer (an exact match);
- Queries without an exact match but with one or several relevant answers (relevant matches);
- Queries without any match at all.
Queries in the second category would be labeled with all relevant QA pairs. When we finished annotating, only 33% of the queries had an exact match, even if 91% of the corpus can be considered “in-domain”. An interesting observation is that the FAQ coverage varied significantly based on the source of the queries, as shown in the table below.
| Source | Count | Exact match | Coverage |
| 275 | 133 | 48.36% | |
| Website queries | 303 | 63 | 20.79% |
| Nu Echo | 440 | 150 | 34.09% |
| Total | 1018 | 346 | 33.99% |
Our explanation is that the Google queries tended to be simpler and more representative of real user queries, the website queries were often out-of-domain, incomplete or ambiguous. The Nu Echo queries tended to be overly “creative” and generally less realistic.
Train and test set
We split our corpus into a train set and a test set. The queries in the train set are used to improve accuracy while the test set is used to measure accuracy. Note that this is a very small test set. It contains 407 queries, of which only 151 have an exact match (37%). It is also very skewed: The top 10% most frequent FAQ pairs account for 61% of those 151 queries.
Performance metrics
To measure performance, we need to decide which performance metrics to use. We opted for precision and recall as our main metrics. They are defined as follows:
- Precision: of all the predictions returned by Dialogflow, how many of them are actually correct?
- Recall: of all the actual responses we’d like to get, how many of them were actually predicted by Dialogflow?
In our case, we considered only exact matches and the top prediction returned by Dialogflow. One reason for this is that relevant matches are fairly subjective and we have found that the agreement between annotators tends to be low. Another reason is that this makes comparison with other techniques (e.g., using defined intents) easier since these techniques may only return one prediction.
Since Dialogflow returns a confidence score that ranges from 0 to 1 for each prediction it makes, we can control the precision-recall tradeoff by changing the confidence threshold. For example:
- when the threshold is at 0, we accept all predictions, and the recall is at its highest, while the precision is usually at its lowest;
- when the threshold is at 1, we exclude almost all predictions, so the recall will be at its lowest, but the precision usually is the highest.
When shown graphically, this provides a very useful visualization that makes it easy to quickly evaluate the performance of an agent against a given set of queries, or to compare agents (see results below).
We’re now ready to delve into some of the experiments we performed. Note that the data that has been used to perform these experiments are publicly available in a Nu Echo GitHub repository.
Experiments with the FAQ Knowledge connector
We took all of the QA pairs we extracted from the airport knowledge base and pushed those to a Dialogflow Knowledge Base FAQ connector. Then we trained an agent and tested this agent with the queries in the test set. Here’s the result.
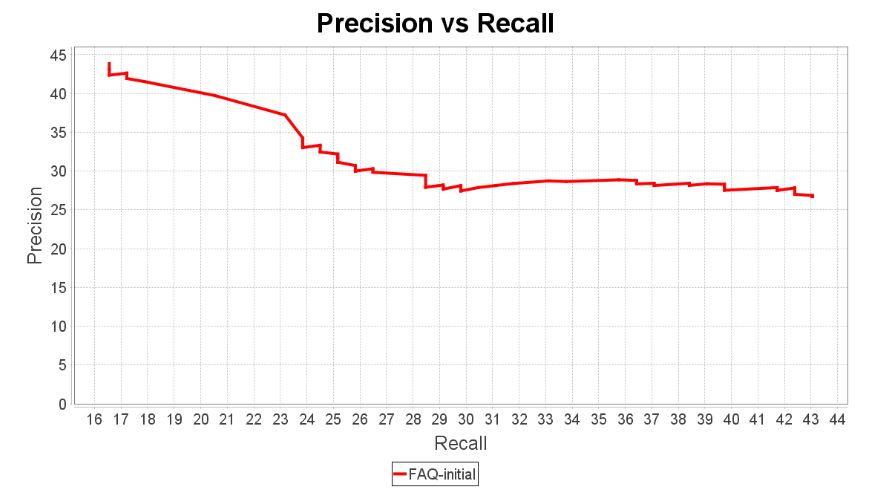
Ouch! This curve shows, at best, a recall of barely 40%. And that’s with less than 30% precision. Something is definitely wrong here. A first analysis of the results reveals something very interesting: The question in the QA pair that correctly answers the user query is often very different from the query. For instance, the correct answer to the query “Can I bring milk with me on the plane for the baby?” is actually found in the QA pair with the following question: “What are the procedures at the security checkpoint when traveling with children?”. In other words, those two formulations are too far apart for any NLU engine to make the connection. In order to identify the correct QA pair, one really has to analyze the answer in order to determine whether it answers the query.
Unfortunately, Dialogflow seems to mostly rely on the question in the QA pair when predicting the best QA pairs and that creates an issue: The more information there is in a FAQ answer, the more difficult it is to reduce it to a single question.
What if QA pairs could have multiple questions?
Contrary to defined intents, Dialogflow FAQ knowledge connectors are limited to a single question per QA pair. While this makes sense if the goal is to use existing FAQ knowledge bases “as is”, it may limit the achievable question answering performance. But what if we work around that restriction by including multiple copies of the same QA pair, but using different question formulations (different questions, same answer)? This could allow us to capture different formulations of the same question, as well as entirely different questions for which the answer is correct.
Here is how we did it:
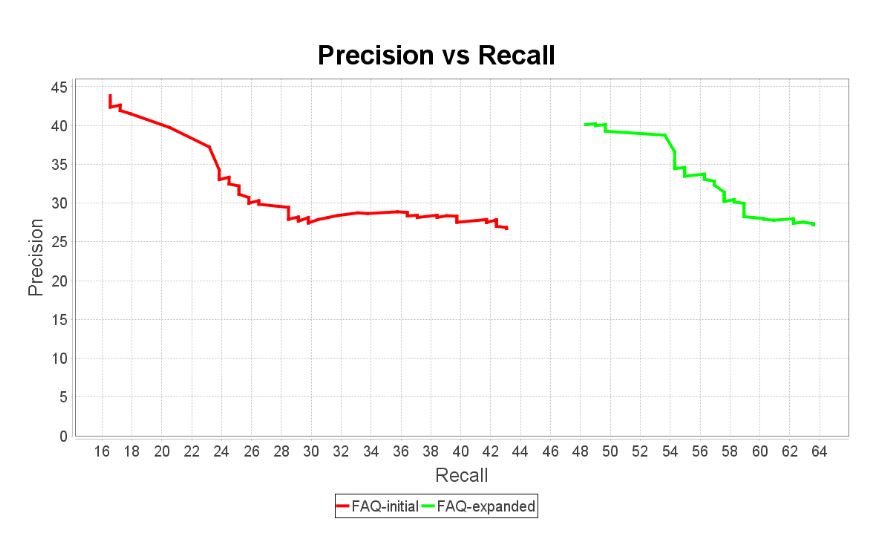
- We selected the top 10 most frequent QA pairs in the corpus. For each of them, we created several new QA pairs containing the same answer, but a different question (using questions from the train set). We called this the expanded FAQ set.
- We created a new agent trained with this expanded set of QA pairs.
- We tested this new agent on the test set.
The graph below compares the performance of this new agent with the original one. There is a definite improvement in recall, but precision still remains very low.
FAQ vs Intents
How do defined intents compare with Knowledge Base FAQ? To find out, we created an agent with one intent per FAQ pair. For each intent, the set of training phrases included the original question in the QA pair, plus all the queries in the train set labelled with that QA pair as an exact match. Then we tested this new agent on the test set. The graph below compares this new result with the previous two results.
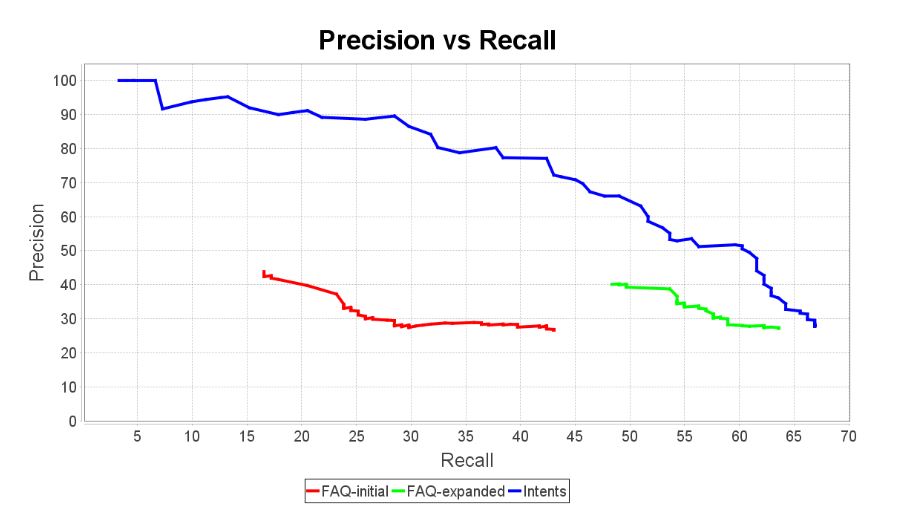
That is an amazing jump in performance. Granted, these are not great results, but at least we know we are heading in the right direction and that performance could still be improved a lot.
A quick look at Knowledge Base Articles
As mentioned before, Dialogflow offers two types of knowledge connectors: FAQ and Knowledge Base Articles. Knowledge Base Articles are based on the technologies used by Google Search, which look for answers to questions by reading and understanding entire documents and extracting a portion of a document that contains the answer to the question. This is often referred to as open-domain question answering.
We wanted to see how this would perform on our FAQ knowledge base. To get the best possible results, we reviewed and edited the FAQ answers to make sure we followed the best practices recommended by Google. This includes avoiding single-sentence paragraphs, converting tables and lists into well-formed sentences, and removing extraneous content. We also made sure that each answer was completely self-contained and could be understood without knowing its FAQ category and sub-category. Finally, whenever necessary, we added text to make it clear what question was being answered. The edited FAQ answers are provided in the Nu Echo GitHub repository.
The result is shown below (green curve, bottom left). What this shows is that Knowledge Base Articles just doesn’t work for that particular knowledge base. The question is: why?
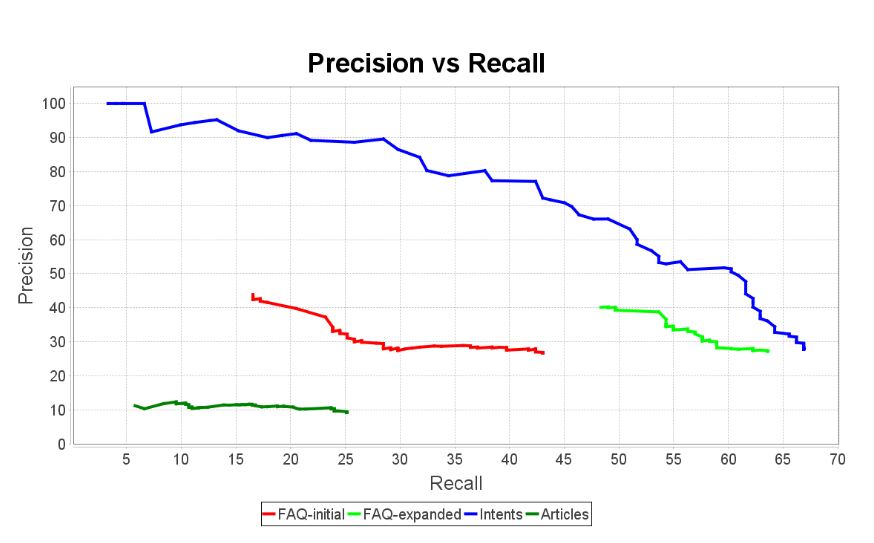
Although further investigation is required, a quick analysis immediately revealed one issue: Some frequent QA pairs don’t actually contain the answer to the user query, but instead provide a link to a document containing the desired information. This may explain why, in those cases, the Article Knowledge Connector couldn’t match the answer to the query.
Conclusion
We wanted to see whether it was possible to achieve good question answering performance by relying solely on Dialogflow Knowledge Connector with existing FAQ knowledge bases. The answer is most likely “no”. Why? There are a number of reasons:
- While defined intents can have as many training phrases as we want, FAQ knowledge bases are limited to a single question per QA pair. This turns out to be a significant problem since it is difficult to effectively generalize from a single example. That’s especially true for QA pairs with long answers, which can correctly answer a wide range of very different questions.
- FAQ knowledge bases are often not representative of real user queries and, therefore, their coverage tends to be low. Moreover, they often need a lot of manual cleanup, which means that we cannot assume that the system will be able to automatically take advantage of an updated FAQ knowledge base.
- Many user queries require a structured representation of the query (i.e., with both intents and entities) and a structured knowledge base to be able to produce the required answer. For instance, to answer the question “Are there any restaurants serving vegan meals near gate 79?”, we need a knowledge base containing all restaurants, their location, and the foods they serve, as well as an algorithm capable of calculating a distance between two locations.
- Many real frequent user queries require access to back-end transactional systems (e.g., “What is the arrival time of flight UA789?”). Again, this cannot be implemented with a static FAQ knowledge base.
The approach we recommend for building a question answering system with Dialogflow is consistent with what Google actually recommends, that is, use Knowledge Connectors to complement defined intents. More specifically, use the power of defined intents, leveraging entities and lots of training phrases, to achieve a high success level on the really frequent questions (the short tail).
Then, for those long tail questions that cannot be answered this way, use knowledge connectors with whatever knowledge bases are available to propose possible answers that the user will hopefully find relevant.
Thanks to Guillaume Voisine and Mathieu Bergeron for doing much of the experimental work and for their invaluable help writing this blog.
